|
Thanks for visiting! I am a Research Engineer at Google DeepMind. I am part of the core Gemini Team currently currently working on Nano Banana . Previously, I was an AI Resident at the Foundational Research Unit at Google DeepMind working on multimodality, efficient thinking and diffusion RL. My work has been used in Gemini 2.5, Gemini 2.0, and Imagen. Before that, I was with Amazon Alexa AI in London working on machine learning for ranking and recommendation. I graduated with an Integrated Masters (BS + MS) in EECS (Electrical and Computer Science Engineering) from IIT Kharagpur . My Thesis was awarded the Best Project Award amongst 2023 graduating students for exceptional research contribution. Email / CV / LinkedIn / GitHub / Google Scholar |

|
|
|
|
|

|
Gemini Team, (includes Nithish Kannen ) Google DeepMind Tech Report In this report, we introduce the Gemini 2.X model family: Gemini 2.5 Pro and Gemini 2.5 Flash, as well as our earlier Gemini 2.0 Flash and Flash-Lite models. Gemini 2.5 Pro is our most capable model yet, achieving SoTA performance on frontier coding and reasoning benchmarks. In addition to its incredible coding and reasoning skills, Gemini 2.5 Pro is a thinking model that excels at multimodal understanding and it is now able to process up to 3 hours of video content. Its unique combination of long context, multimodal and reasoning capabilities can be combined to unlock new agentic workflows. Gemini 2.5 Flash provides excellent reasoning abilities at a fraction of the compute and latency requirements and Gemini 2.0 Flash and Flash-Lite provide high performance at low latency and cost. Taken together, the Gemini 2.X model generation spans the full Pareto frontier of model capability vs cost, allowing users to explore the boundaries of what is possible with complex agentic problem solving. |
|
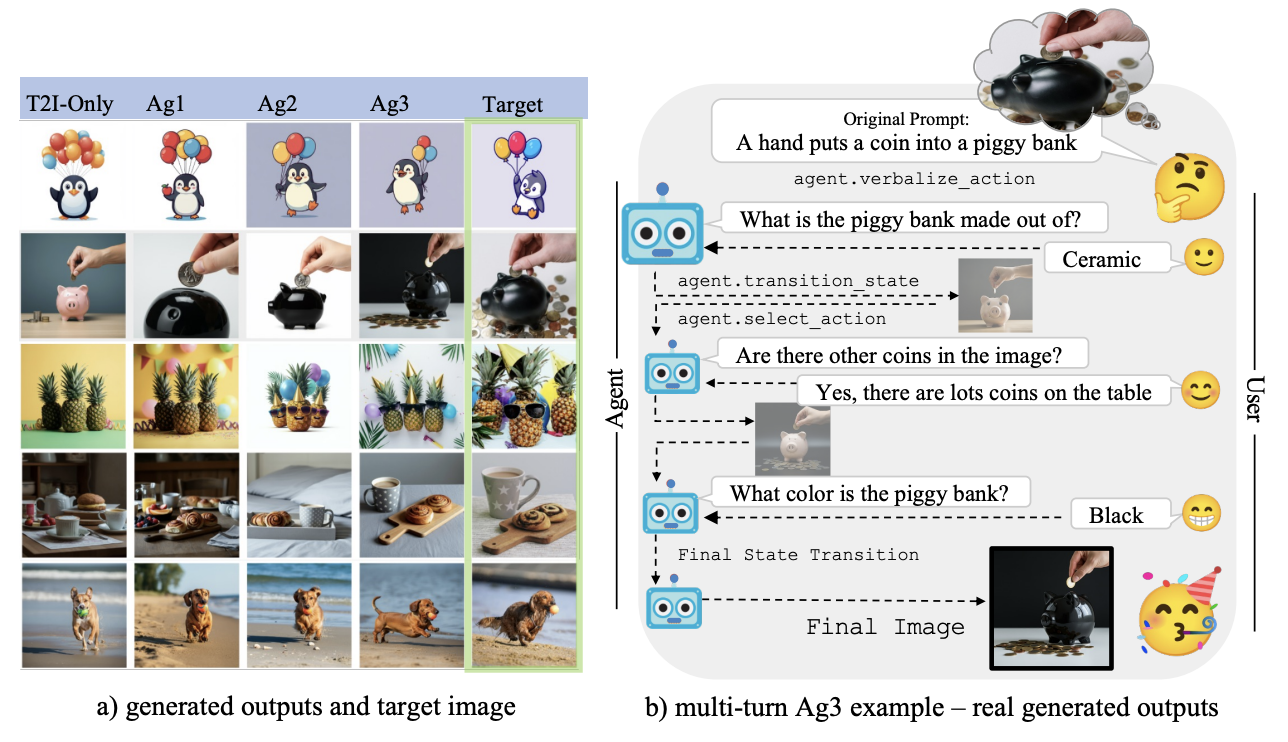
Meera Hahn, Wenjun Zeng, Nithish Kannen , Rich Galt, Kartikeya Badola, Been Kim, Zi Wang ICML 2025 paper | code User prompts for generative AI models are often underspecified, leading to sub-optimal responses. This problem is particularly evident in text-to-image (T2I) generation, where users commonly struggle to articulate their precise intent. This disconnect between the user's vision and the model's interpretation often forces users to painstakingly and repeatedly refine their prompts. To address this, we propose a design for proactive T2I agents equipped with an interface to (1) actively ask clarification questions when uncertain, and (2) present their understanding of user intent as an understandable belief graph that a user can edit. We build simple prototypes for such agents and verify their effectiveness through both human studies and automated evaluation. We observed that at least 90% of human subjects found these agents and their belief graphs helpful for their T2I workflow. Moreover, we develop a scalable automated evaluation approach using two agents, one with a ground truth image and the other tries to ask as few questions as possible to align with the ground truth. On DesignBench, a benchmark we created for artists and designers, the COCO dataset (Lin et al., 2014), and ImageInWords (Garg et al., 2024), we observed that these T2I agents were able to ask informative questions and elicit crucial information to achieve successful alignment with at least 2 times higher VQAScore (Lin et al., 2024) than the standard single-turn T2I generation |
|
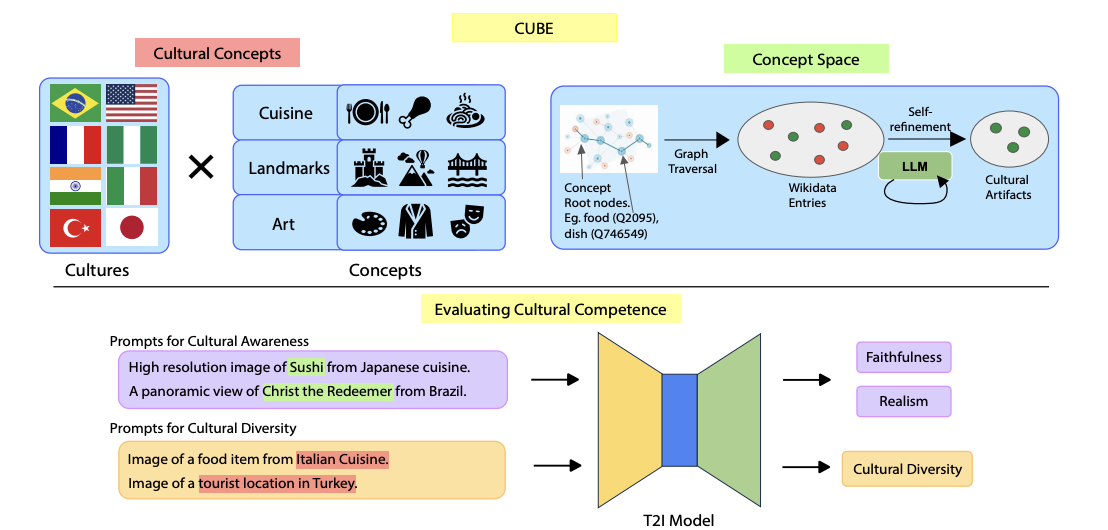
Nithish Kannen , Arif Ahmad, Marco Andreetto, Vinodkumar Prabhakaran, Utsav Prabhu, Adji Bousso Dieng, Pushpak Bhattacharyya, Shachi Dave NeurIPS 2024 (D&B) paper | code Text-to-Image (T2I) models are being increasingly adopted in diverse global communities where they create visual representations of their unique cultures. Current T2I benchmarks primarily focus on faithfulness, aesthetics, and realism of generated images, overlooking the critical dimension of cultural competence. In this work, we introduce a framework to evaluate cultural competence of T2I models along two crucial dimensions: cultural awareness and cultural diversity, and present a scalable approach using a combination of structured knowledge bases and large language models to build a large dataset of cultural artifacts to enable this evaluation. In particular, we apply this approach to build CUBE (CUltural BEnchmark for Text-to-Image models), a first-of-its-kind benchmark to evaluate cultural competence of T2I models. CUBE covers cultural artifacts associated with 8 countries across different geo-cultural regions and along 3 concepts: cuisine, landmarks, and art. CUBE consists of 1) CUBE-1K, a set of high-quality prompts that enable the evaluation of cultural awareness, and 2) CUBE-CSpace, a larger dataset of cultural artifacts that serves as grounding to evaluate cultural diversity. We also introduce cultural diversity as a novel T2I evaluation component, leveraging quality-weighted Vendi score. Our evaluations reveal significant gaps in the cultural awareness of existing models across countries and provide valuable insights into the cultural diversity of T2I outputs for under-specified prompts. Our methodology is extendable to other cultural regions and concepts, and can facilitate the development of T2I models that better cater to the global population. |
|
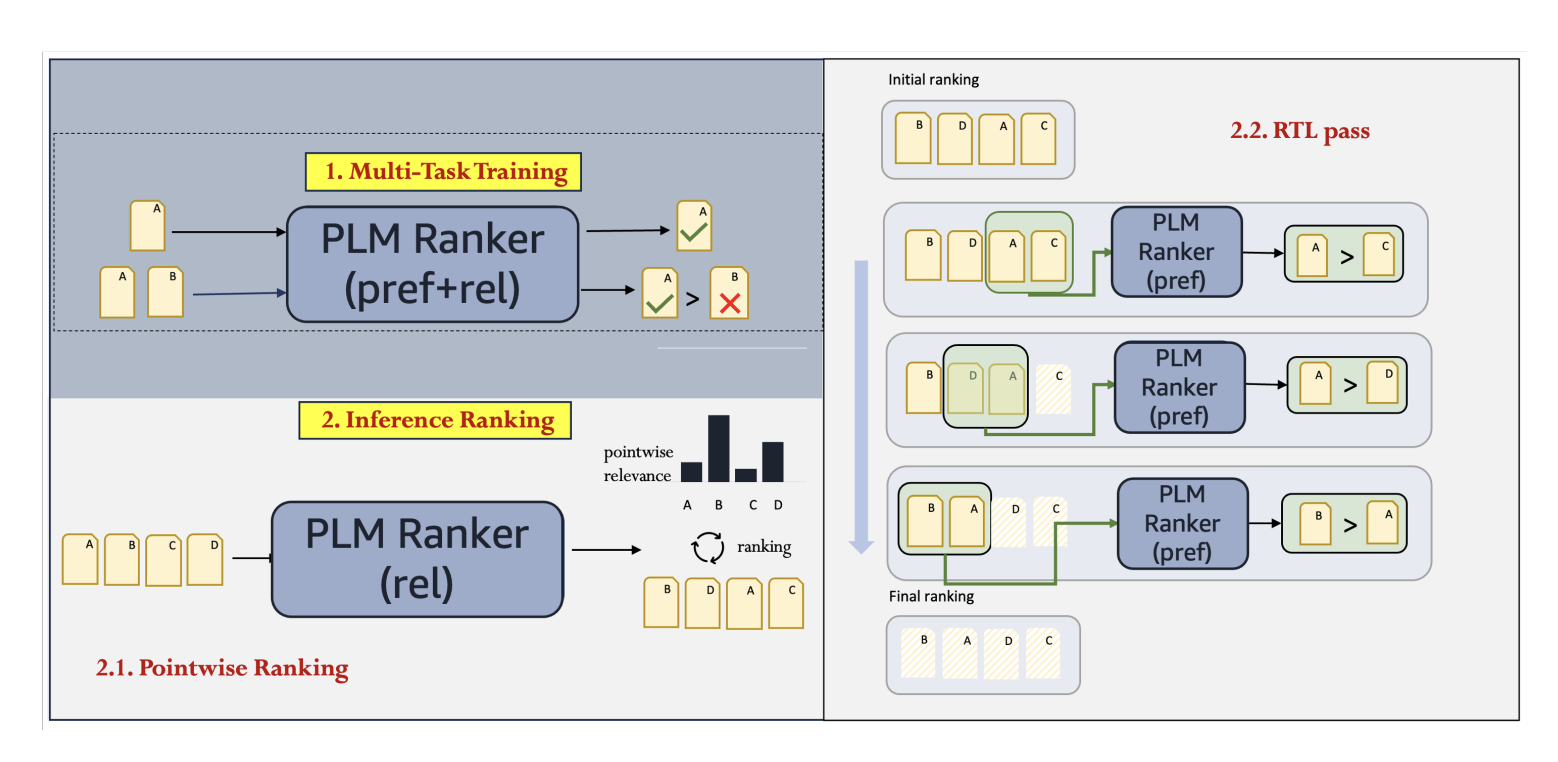
Nithish Kannen , Yao Ma, Gerrit van der Burg, Jean Baptiste Faddoul EMNLP 2024 paper News recommendation is a challenging task that involves personalization based on the interaction history and preferences of each user. Recent works have leveraged the power of pretrained language models (PLMs) to directly rank news items by using inference approaches that predominately fall into three categories: pointwise, pairwise, and listwise learning-to-rank. While pointwise methods offer linear inference complexity, they fail to capture crucial comparative information between items that is more effective for ranking tasks. Conversely, pairwise and listwise approaches excel at incorporating these comparisons but suffer from practical limitations: pairwise approaches are either computationally expensive or lack theoretical guarantees and listwise methods often perform poorly in practice. In this paper, we propose a novel framework for PLM-based news recommendation that integrates both pointwise relevance prediction and pairwise comparisons in a scalable manner. We present a rigorous theoretical analysis of our framework, establishing conditions under which our approach guarantees improved performance. Extensive experiments show that our approach outperforms the state-of-the-art methods on the MIND and Adressa news recommendation datasets. |
|
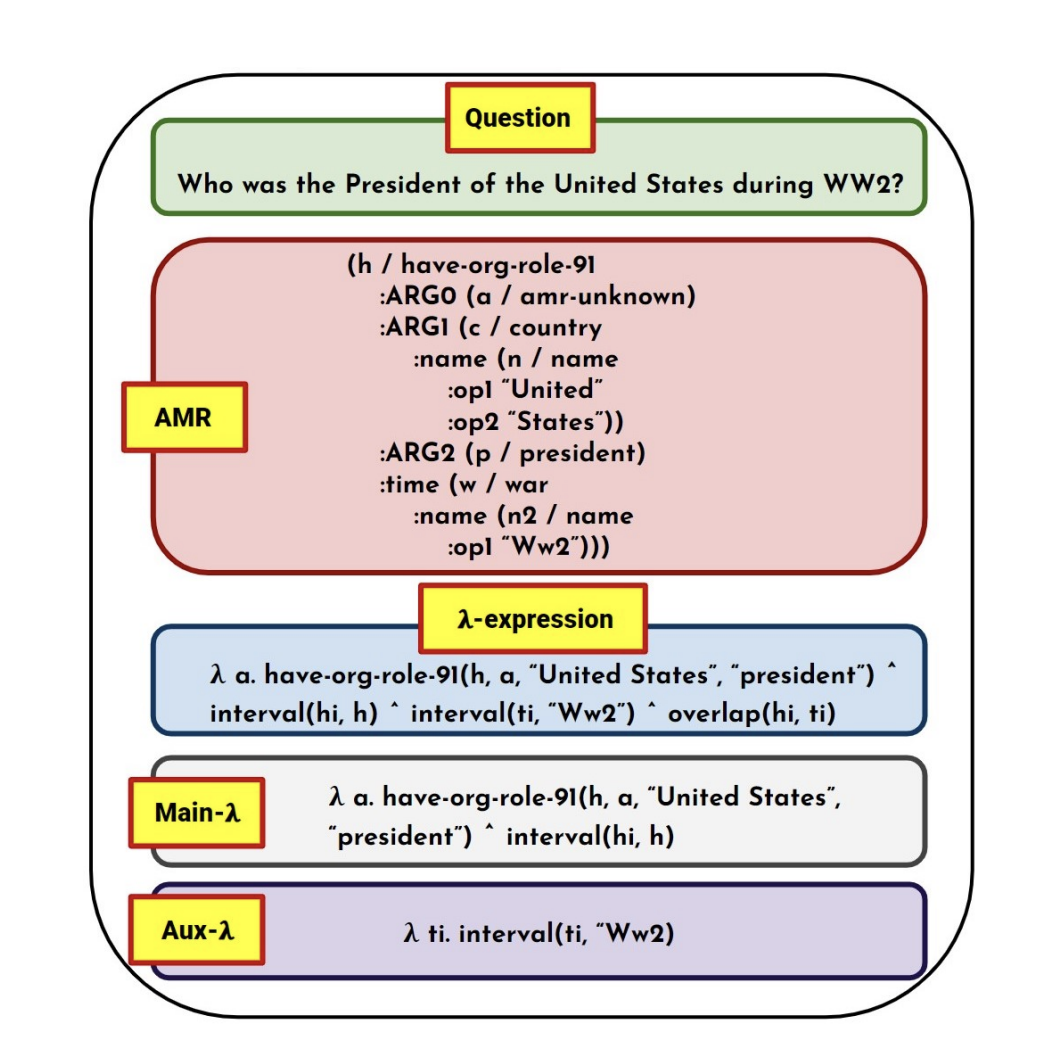
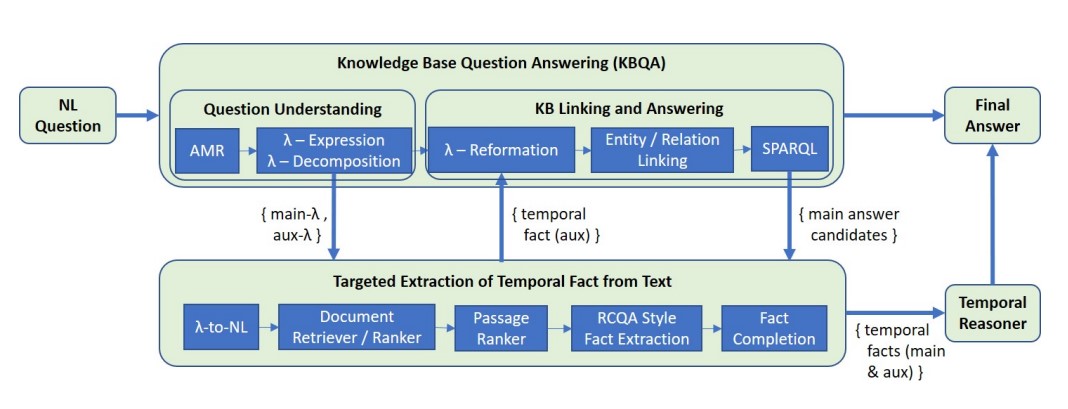
Nithish Kannen , Udit Sharma, Sumit Neelam, Dinesh Khandelwal, Shajith Ikbal, Hima Karanam, L Venkata Subramaniam EMNLP 2023 paper Temporal question answering (QA) is a special category of complex question answering task that requires reasoning over facts asserting time intervals of events. Previous works have predominately relied on Knowledge Base Question Answering (KBQA) for temporal QA. One of the major challenges faced by these systems is their inability to retrieve all relevant facts due to factors such as incomplete KB and entity/relation linking errors (Patidar et al., 2022). A failure to fetch even a single fact will block KBQA from computing the answer. Such cases of KB incompleteness are even more profound in the temporal context. To address this issue, we explore an interesting direction where a targeted temporal fact extraction technique is used to assist KBQA whenever it fails to retrieve temporal facts from the KB. We model the extraction problem as an open-domain question answering task using off-the-shelf language models. This way, we target to extract from textual resources those facts that failed to get retrieved from the KB. Experimental results on two temporal QA benchmarks show promising 30% & 10% relative improvements in answer accuracies without any additional training cost. |
|
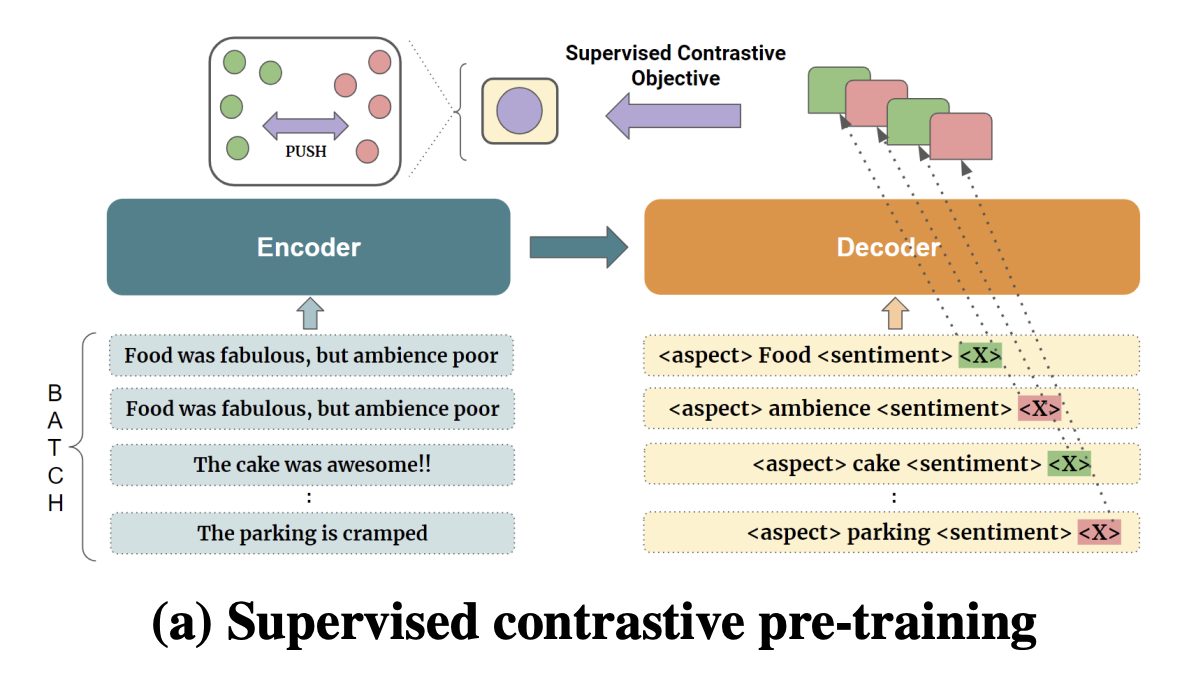
Rajdeep Mukherjee, Nithish Kannen , Saurabh Kumar Pandey, Pawan Goyal EMNLP 2023 (Findings) paper | code Existing works on Aspect Sentiment Triplet Extraction (ASTE) explicitly focus on developing more efficient fine-tuning approaches for the task. Different from these, we propose CONTRASTE, a novel pre-training strategy using CONTRastive learning to improve the performance of the downstream ASTE task. Given a sentence and its associated (aspect, opinion, sentiment) triplets, first, we design aspect-based prompts with corresponding sentiments masked. We then (pre)train an encoder-decoder architecture by applying contrastive learning on the decoder-generated aspect-aware sentiment representations of the masked terms. For fine-tuning the pre-trained model weights thus obtained, we then propose a novel multi-task approach where the base encoder-decoder framework is combined with two complementary modules, a tagging-based Opinion Term Detector, and a regression-based Triplet Count Estimator. Exhaustive experiments on four benchmark datasets and a detailed ablation study establish the importance of each of our proposed components as we achieve new state-of-the-art results for the ASTE task. We further demonstrate that our proposed pre-training scheme can improve the performance of other ABSA tasks such as Aspect Category Opinion Sentiment (ACOS) quad prediction, Target Aspect Sentiment Detection (TASD), and Aspect Extraction and Sentiment Classification (AESC). |
|
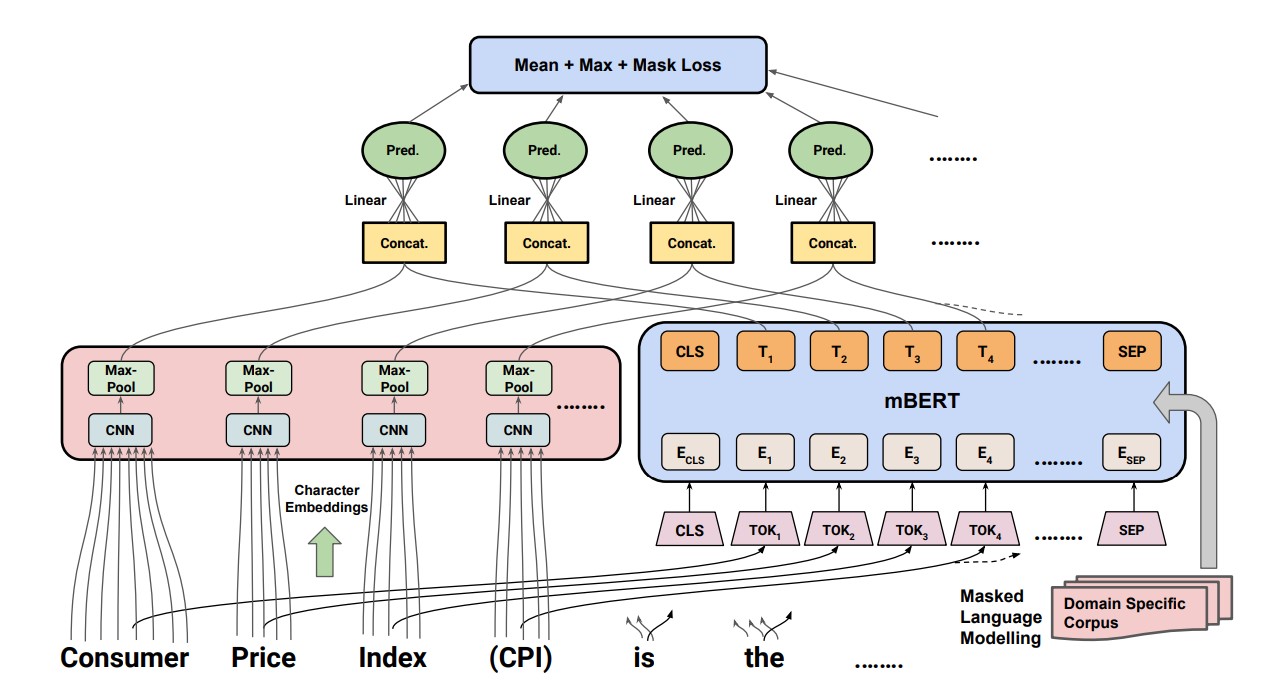
Nithish Kannen , Divyanshu Sheth, Abhranil Chandra, Shubraneel Pal Scientific Document Understanding (SDU) at Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI) 2022 paper | code Acronyms and long-forms are a common sight in research documents in general, more so in documents from scientific and legal domains. Many of the acronyms used in these documents are domain-specific, and are very rarely found in normal text corpora. Owing to this, transformer-based NLP models suffer while detecting OOV (Out of Vocabulary) for acronym tokens and their performance suffers while linking acronyms to their long forms during extraction. Moreover, transformer-based models like BERT are not specialized to handle scientific and legal documents. With these points being the overarching motivation behind this work, we propose a novel framework CABACE: Character-Aware BERT for ACronym Extraction, that takes into account character sequences in text, and is adapted to the scientific and legal domains by masked language modelling. We further use an objective function with augmented loss function, adding mask + max loss for training CABACE. Experimental results prove the superiority of the proposed framework in comparison to various baselines. Additionally, we show that the proposed framework is better suited than baseline models for zero-shot generalization to non-English languages, thus reinforcing the effectiveness of our approach. Our team BacKGProp secured the highest scores on the French dataset, second highest on Danish and Vietnamese, and third highest in the Legal English dataset on the global Codalab leaderboard for the acronym extraction shared task at SDU AAAI-22. |
|
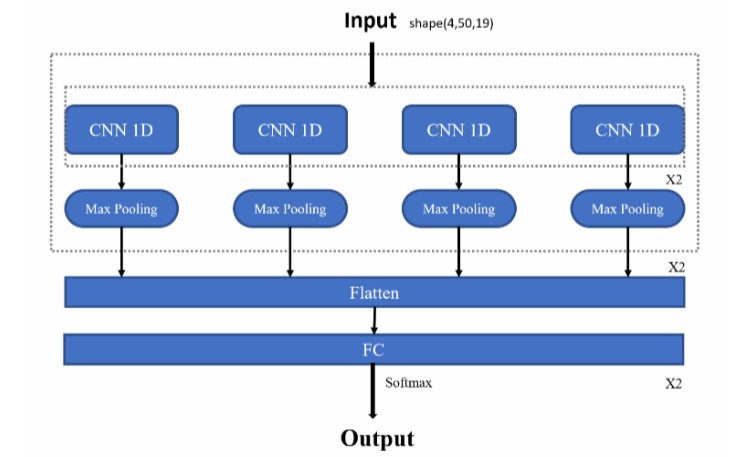
Nithish Kannen , Abdulhamit Subasi Chapter in Advanced Signal Processing for Industry 4.0, Volume 2 In this chapter, we present a user-dependent and independent deep learning-based approach for transportation mode recognition using smartphone sensor data. Moreover, comparative experiments over six deep learning models including the Convolutional and Recurrent Neural Networks are conducted to determine the best position of the smartphone for transportation mode recognition. |
|
Nithish Kannen , Udit Sharma, Sumit Neelam, Dinesh Khandelwal, Shajith Ikbal, Hima Karanam, L Venkata Subramaniam Preprint paper | Knowledge Base Question Answering (KBQA) systems have the goal of answering complex natural language questions by reasoning over relevant facts retrieved from Knowledge Bases (KB). One of the major challenges faced by these systems is their inability to retrieve all relevant facts due to factors such as incomplete KB and entity/relation linking errors. In this paper, we address this particular challenge for systems handling a specific category of questions called temporal questions, where answer derivation involve reasoning over facts asserting point/intervals of time for various events. We propose a novel approach where a targeted temporal fact extraction technique is used to assist KBQA whenever it fails to retrieve temporal facts from the KB. We use λ-expressions of the questions to logically represent the component facts and the reasoning steps needed to derive the answer. This allows us to spot those facts that failed to get retrieved from the KB and generate textual queries to extract them from the textual resources in an open-domain question answering fashion. We evaluated our approach on a benchmark temporal question answering dataset considering Wikidata and Wikipedia respectively as the KB and textual resource. Experimental results show a significant ∼30\% relative improvement in answer accuracy, demonstrating the effectiveness of our approach. |
|
|

|
Collaborators: Partha Talukdar, Shachi Dave, Vinodkumar Prabhakaran, Zi Wang, Marco Andreetto, Multimodal models, Safety, Alignment, Agents. Work published at NeurIPS 2024, ICLR 2025. |

|
Collaborators: Yao Ma, Gerrit J.J. van den Burg, Jean Baptiste Faddoul Machine Learning for Ranking, Recommendation. Work published at EMNLP 2024. |

|
Supervisor(s): Markus Boese and Caglar Tirkaz (now at Apple AI) Was part of the Golden Eagle Science team with a focus on Alexa AI - Natural Language Understanding. Developed a multi-task generative framework using Prompt Learning as a controllable utterance generator for intent classification and slot labelling. Manuscript detailing our work is under preparation for ACL 2023. |

|
Supervisor(s): Shajith Ikbal, Hima Karanam and LV Subramaniam Worked with the Neuro-Symbolic AI team on targetted temporal fact extraction from textual resource to aid Complex Question Answering over Knoweledge Base via Temporal Reasoning. Work published at EMNLP 2023. |
|
Supervisor(s): Prof. Pawan Goyal 1 ) Working on a Meta Learning framework for Cross Lingual Question Generation and Question Answering. 2) Working on a tagging free approach for Aspect Sentiment Triplet Extraction using syntactic features and Graph Neural Networks (GATs). Work published in EMNLP 2023. |

|
Supervisor(s): Prof. Abdulhamit Subasi Worked on classification of heart diseases using Signal Processing and Deep Learning techniques based on Stethoscope audio data. |
|
|
|
Acronym Extraction Shared Task at AAAI-22 (SDU) Proposed a novel unified character-aware framework for Acronym and Long-Form extraction using domain specific language modelling and optimized objective function. Our team secured the highest score on French, and 2nd highest score on Vietnamese, Danish and Legal English on the global Codalab leaderboard. |
|
Bachelor Thesis (Mid) |Advisor: Prof. Pawan Goyal Proposed a novel framework for Cross Lingual question generation inspired from Meta Learning and Adversarial Training. Experimented with data augmentation techniques and robustness of QA and QG systems to context shuffling. Work planned for submission to TALIP Journal. |
|
Artificial Intelligence Foundations and Applications Term Project |Advisors: Prof. Partha Pratim Chakrabarti and Prof. Arijit Mondal Proposed a novel Multi‑Agent Path Finding Algorithm to perform a set of pickup‑delivery tasks in a pre‑defined warehouse map using Multi‑Label A*. Performed agent‑task pair scheduling using IDA* algorithm and implemented Floyd Warshall for computing heuristics on the implicit graph |
|
|

|
Senior Editor (Apr' 20 - Jun' 21)
IIT Tech Ambit (My Profile) Official tech magazine of the IITs, developed at IIT Kharagpur that identifies research carried out by the stakeholders of IITs and their impact. Authored numerous articles for monthly magazines. Interviewed stakeholders and achievers within KGP and outside |

|
Core Member (Sept '20 - Jun '21)
Kharagpur Data Analytics Group (KDAG), IIT Kharagpur Organized research paper-reading sessions for students of IIT Kharagpur. Conducted Data Science and ML workshop for more than 600 registered students. The KDAG is a group of students enthusiastic about Data Science and Machine Learning, along with its applications. |
| Thanks to Jon Barron for sharing this awesome template! |